
List 자료형으로 데이터를 가지고 Dataframe을 만들고 싶었다.
안녕하세요? 데이터위자드입니다.
오늘 시간에는, 파이썬 Pandas 라이브러리를 사용 내용 중, dataframe를 최초 생성하는 방법에 대해서 알아보겠습니다.
데이터프레임을 최초 만드는 방법은 보통,
- List 자료형을 가져와서 할당하기
- Excel 파일이나 csv파일에서 불러오기(Import)
- SQL과 같은 RDBMS에서 가져오기
정도가 될 거 같네요.
오늘은 그중에서 List 변수를 가져와서 dataframe을 생성하는 것에 대해서 이야기해 보겠습니다. 역시나 사용하게 될 파이썬 라이브러리는 Pandas입니다. (두 번 세 번 말하기도 민망하네요.)
https://pypi.org/project/pandas/
pandas
Powerful data structures for data analysis, time series, and statistics
pypi.org
Pandas는 이외에도 다양한 기능을 가지고 있으니, 평소 사용빈도가 높으시다면 시간을 투자해 자세히 알아보는 것도 좋을 것입니다.
Pandas를 이용한 데이터 분석 실습:라이브러리로 다양한 실제 데이터 분석
COUPANG
www.coupang.com
각설하고, 본론으로 들어가겠습니다.
당연하게도, 처음은 데이터 프레임 처리를 위해 pandas 패키지를 import 하여 줍니다.
List 자료형 변수 생성
먼저 데이터프레임에 사용할 List를 생성하도록 하겠습니다. (예시를 위해, 주식투자 RPA에 있는 예제를 사용하였습니다.)
List형을 가지고 dataframe 생성
다음으로, 위 두 개의 list형 변수를 가지고 데이터프레임을 만들고 List 내 변수를 해당 dataframe에 할당합니다.
기존에 생성된 열(Columns)을 가지고 새로운 열을 생성
그리고, 'code'열을 가지고 'yes_high' 열을 생성하면서 복사하여 줍니다.
for - in 명령어를 이용해 새로 생성된 열에 초기값을 설정
위에서, 'code'열의 데이터를 가지고 'yes_high' 열에 그대로 복사해 줬기 때문에, 'yes_high'열의 데이터를 초기화해 줄 필요가 있습니다.
반복된 작업을 피하기 위해 for - in 명령어를 이용하여 훨씬 간결하게 작성하도록 합니다.
해당 코드를 실행하고, 데이터프레임을 출력하면 다음과 같습니다.
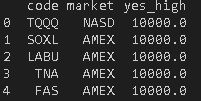
dataframe이 잘 생성된 것을 보실 수 있습니다.

참고하시어, 즐거운 데이터 생활 되시길 바랍니다.
* 본 포스팅에서 언급된 라이브러리, 단체는 필자와 무관함을 알립니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
도움이 되셨다면, 왼쪽 아래 '💗' 클릭 부탁드립니다. 감사합니다.
'맨땅에 프로그래밍 > Python 복기장' 카테고리의 다른 글
| Python으로 반올림, 올림, 내림 처리하기(feat. round, ceil, floor) (0) | 2024.04.29 |
|---|---|
| Python으로 미국 현지 Summer time 확인 자동화 하기 (feat. pytz) (2) | 2024.04.15 |
| Dataframe에서 특정 조건을 만족하는 행만 추출하기(Feat. Pandas) (0) | 2024.04.04 |
| Python으로 적정 원달러 환율 구하기(feat. 달러 투자 무작정 따라하기) (0) | 2024.03.27 |
| Fear & Greed Index(공탐지수) Python으로 가져오기 (0) | 2024.03.05 |